云從科技在權(quán)威多模態(tài)大模型評測體系OpenCompass排名中國第一 全球第三
近日,云從科技從容大模型在綜合評測權(quán)威平臺OpenCompass的多模態(tài)評測領(lǐng)域中取得重大進(jìn)展。
最新評測結(jié)果顯示,云從科技的從容大模型在該體系中的平均得分為65.5,這一成績使得從容大模型躋身全球前三,超越了谷歌的Gemini-1.5-Pro和GPT-4v,僅次于GPT-4o(69.9)和Claude3.5-Sonnet(67.9)。而在國內(nèi)市場,從容大模型的成績也超過了InternVL-Chat(61.7)和GLM-4V(60.8),排名首位。
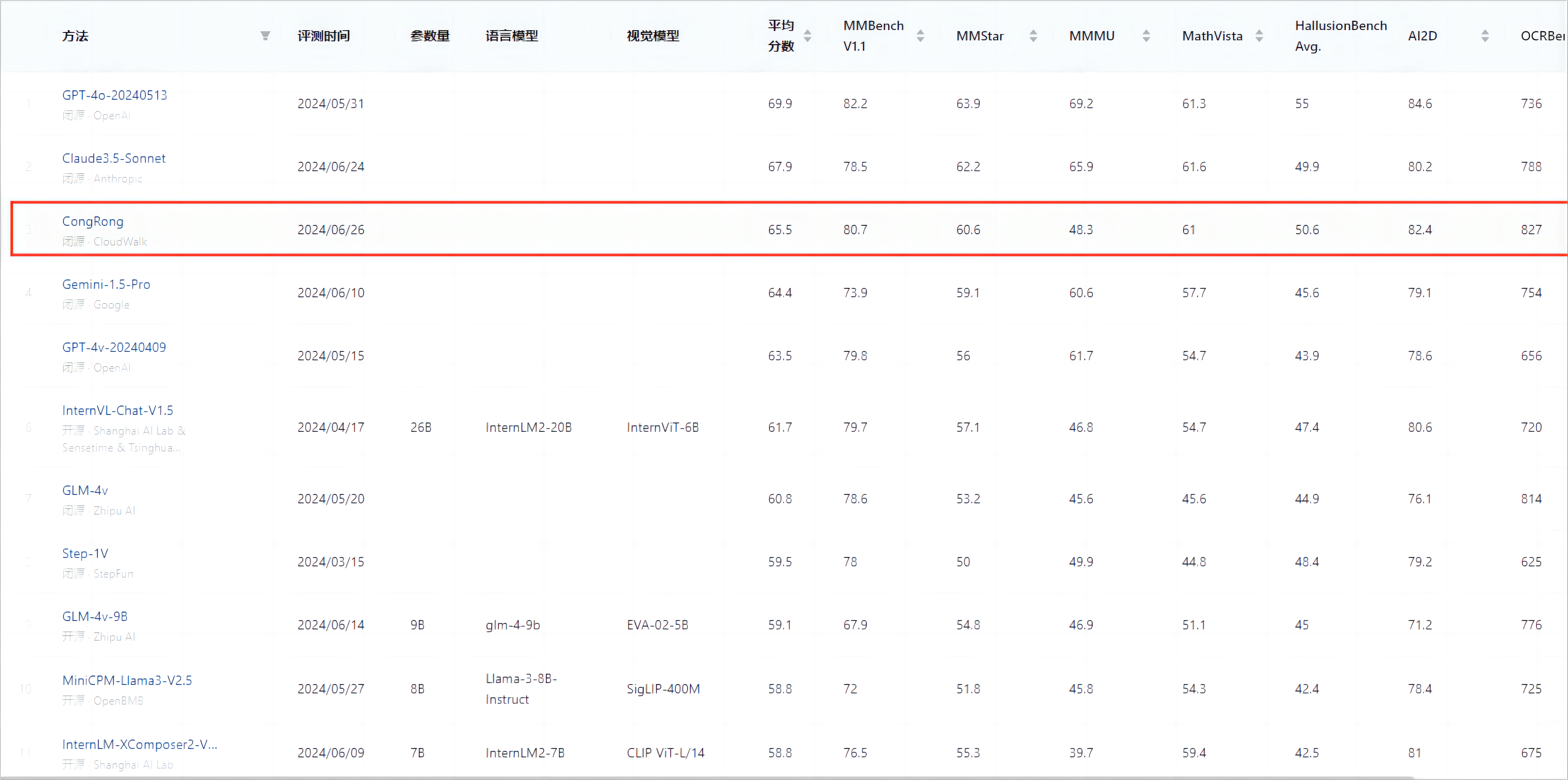
圖1:OpenCompass多模態(tài)榜單
OpenCompass大模型開放評測體系是上海人工智能實(shí)驗(yàn)室推出的完整開源可復(fù)現(xiàn)的評測框架。OpenCompass多模態(tài)評測方面采用了8個具有代表性的數(shù)據(jù)集,從多種視角客觀量化多模態(tài)大模型的能力,評估維度覆蓋目標(biāo)檢測、文字識別、動作識別、圖像理解和關(guān)系推理、藝術(shù)與設(shè)計、商業(yè)、科學(xué)、健康與醫(yī)學(xué)、人文與社會科學(xué)、技術(shù)與工程、數(shù)學(xué)推理等多個方面。
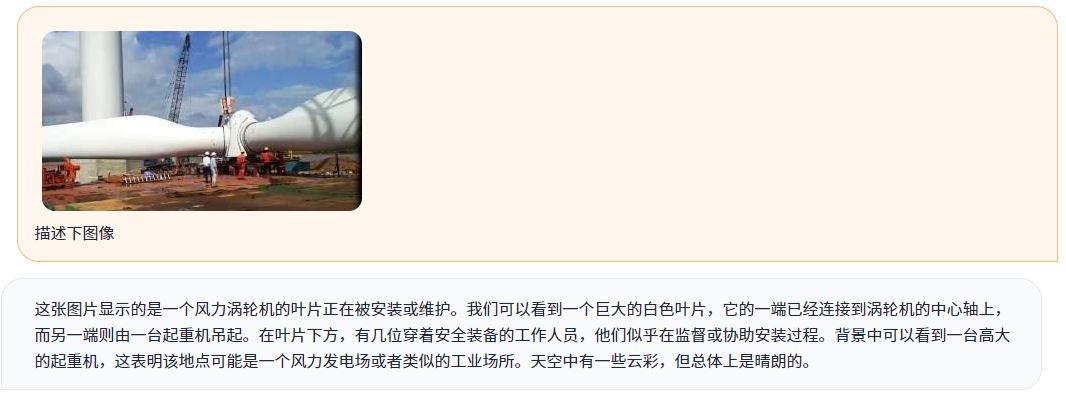 圖2:從容大模型-2.0多模態(tài)能力示例
圖2:從容大模型-2.0多模態(tài)能力示例
在本次測評中,從容大模型在其中的6個數(shù)據(jù)集表現(xiàn)優(yōu)異,排名國內(nèi)第一(MMbench、MMStar、MathVista、HallusionBench、AI2D、OCRBench),尤其是在OCRBench測試集上以取得全球最高的827分(總分為1000分),且高于第二名GLM-4v 13分,進(jìn)一步提升從容大模型在文本識別、以文本為中心的視覺問答、面向文檔的視覺問答、關(guān)鍵信息提取等業(yè)務(wù)場景下的適用性。
圖3:OpenCompass中國大模型多模態(tài)能力展示
從容大模型在此體系中的優(yōu)秀表現(xiàn),依賴云從科技自研的高效多模態(tài)處理架構(gòu)和先進(jìn)的計算技術(shù),實(shí)現(xiàn)了高效的多模態(tài)數(shù)據(jù)處理能力,能夠在視覺和語言任務(wù)之間實(shí)現(xiàn)高效的融合和切換,并最大化利用計算資源,保證在處理大規(guī)模多模態(tài)數(shù)據(jù)時仍能保持較高的性能和響應(yīng)速度,使得模型的訓(xùn)練過程更加高效,收斂速度更快,性能更穩(wěn)定。
同時也得益于云從科技長期在視覺、語言領(lǐng)域的深厚積累和不斷創(chuàng)新。
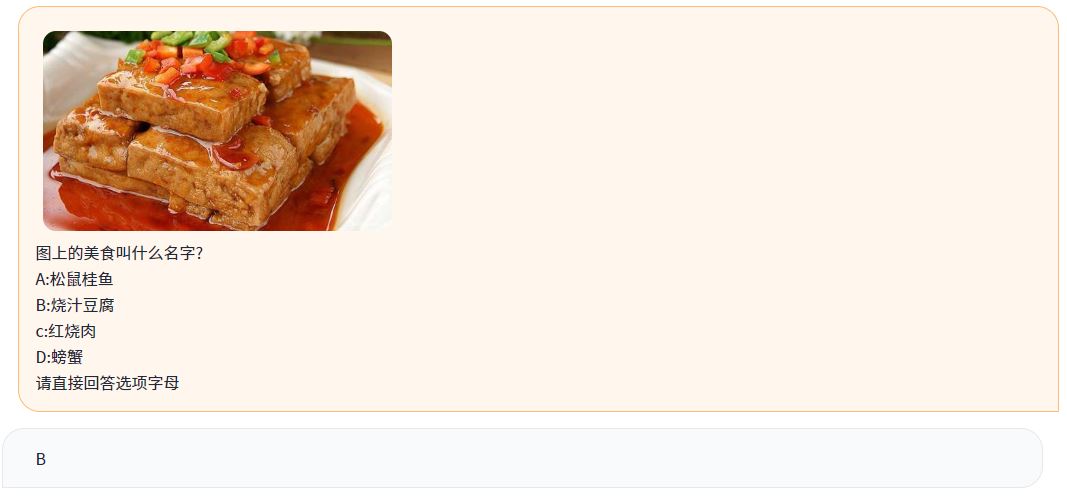 圖4:從容大模型-2.0多模態(tài)能力示例
圖4:從容大模型-2.0多模態(tài)能力示例
此前,從容大模型已在視覺、跨模態(tài)領(lǐng)域10次刷新世界紀(jì)錄,綜合性能經(jīng)第三方SuperClue、C-Eval等綜合評測,位列全球前五。
作為一家專注于人機(jī)協(xié)同技術(shù)研發(fā)的平臺企業(yè),云從科技一直在積極推動AI智能體及大模型技術(shù)的發(fā)展和應(yīng)用。
隨著人工智能技術(shù)的迅猛發(fā)展,多模態(tài)大模型已成為驅(qū)動產(chǎn)業(yè)變革的核心引擎。此次從容大模型在OpenCompass大模型開放評測體系中的出色表現(xiàn),不僅是對云從科技技術(shù)創(chuàng)新實(shí)力的認(rèn)可,更在業(yè)界樹立典范,激勵全球科技企業(yè)在新一輪的人工智能競爭中勇攀高峰。
您可能感興趣
-
 2024-08-08
2024-08-08近日,重慶市經(jīng)濟(jì)信息委員會公布本年度首批市級首版次軟件產(chǎn)品名錄。云從科技從容大模型訓(xùn)推一體機(jī)系統(tǒng)以其卓越的兼容性和技術(shù)創(chuàng)新力脫穎而出,成功入選。
-
 2024-12-20
2024-12-20近日,2024年“中國品牌年度大獎”評選在“世界經(jīng)理人峰會”上揭曉。這項被譽(yù)為“中國品牌奧斯卡”的年度獎項,由業(yè)界權(quán)威機(jī)構(gòu)世界品牌實(shí)驗(yàn)室(World Brand Lab)于12月18日在香港頒發(fā)。 云從科技憑借其在人工智能領(lǐng)域的杰出貢獻(xiàn)和創(chuàng)新成果,榮膺2024年度“中國科技創(chuàng)新十大影響力品牌”。
-








